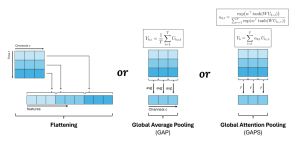
This project started as a Bachelor’s Thesis and was continued beyond.
Thesis and defense were each graded 4.0 (equivalent to 1.0 in German grading system).

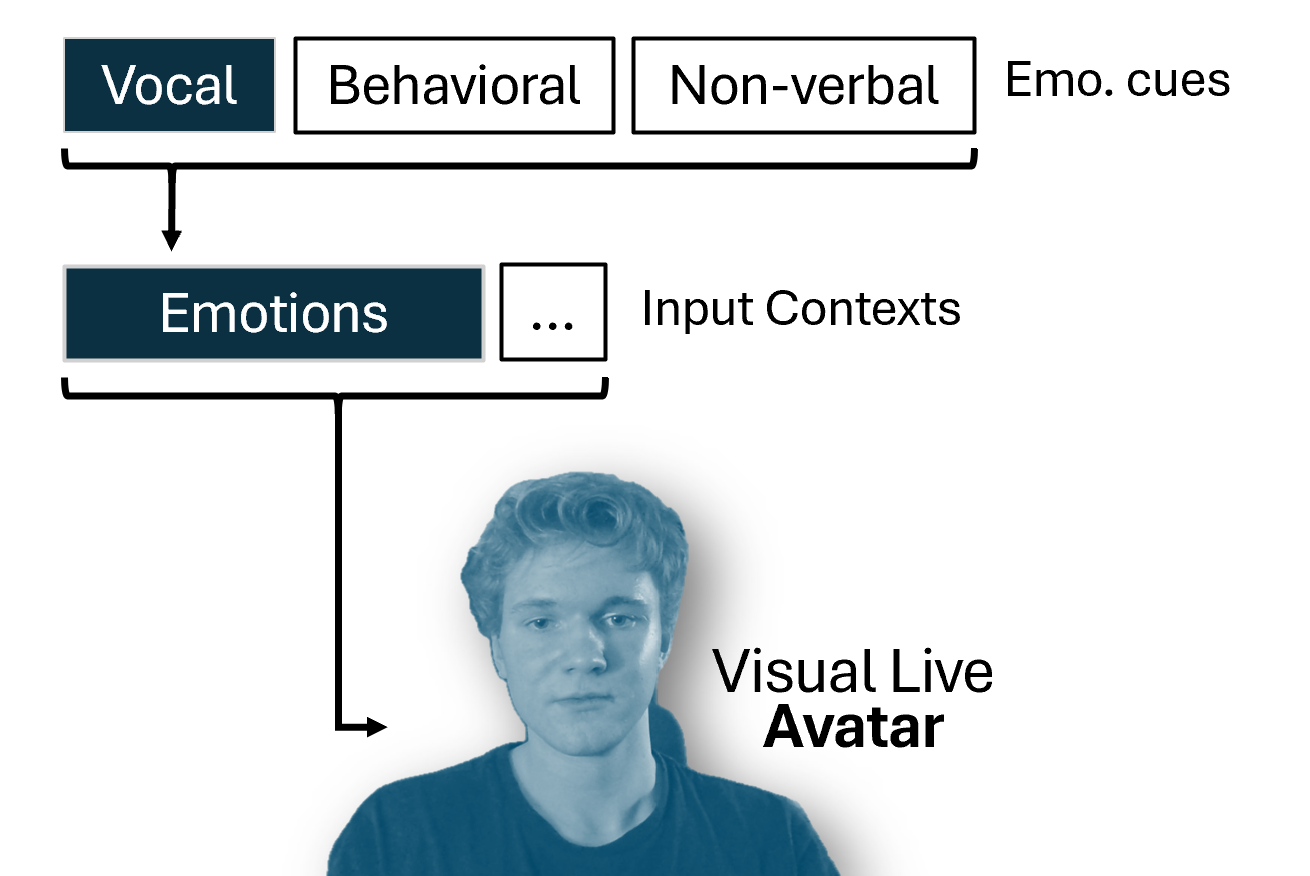
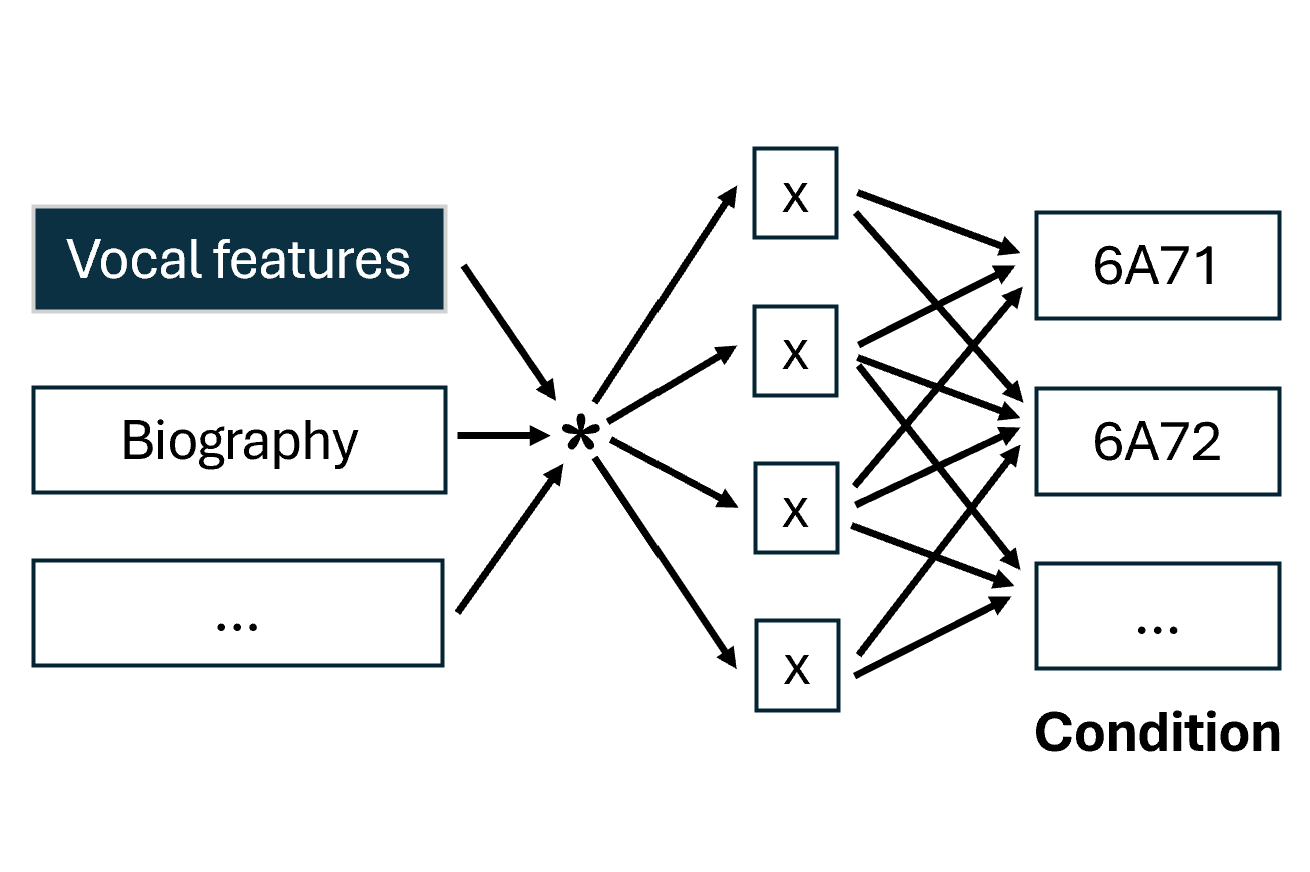
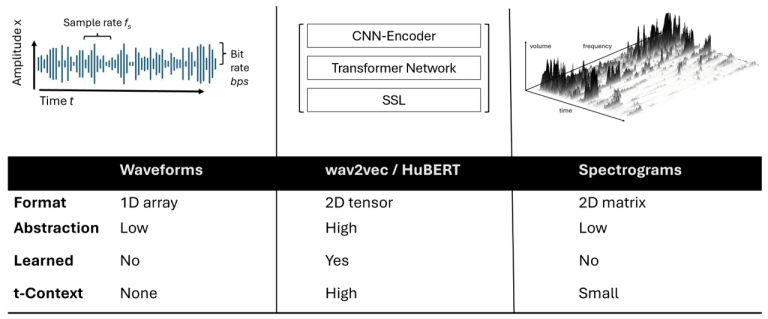
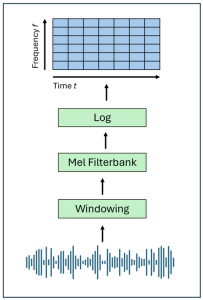
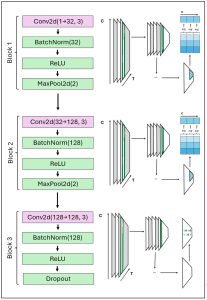
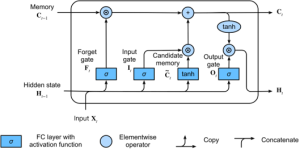
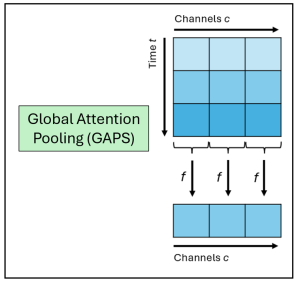
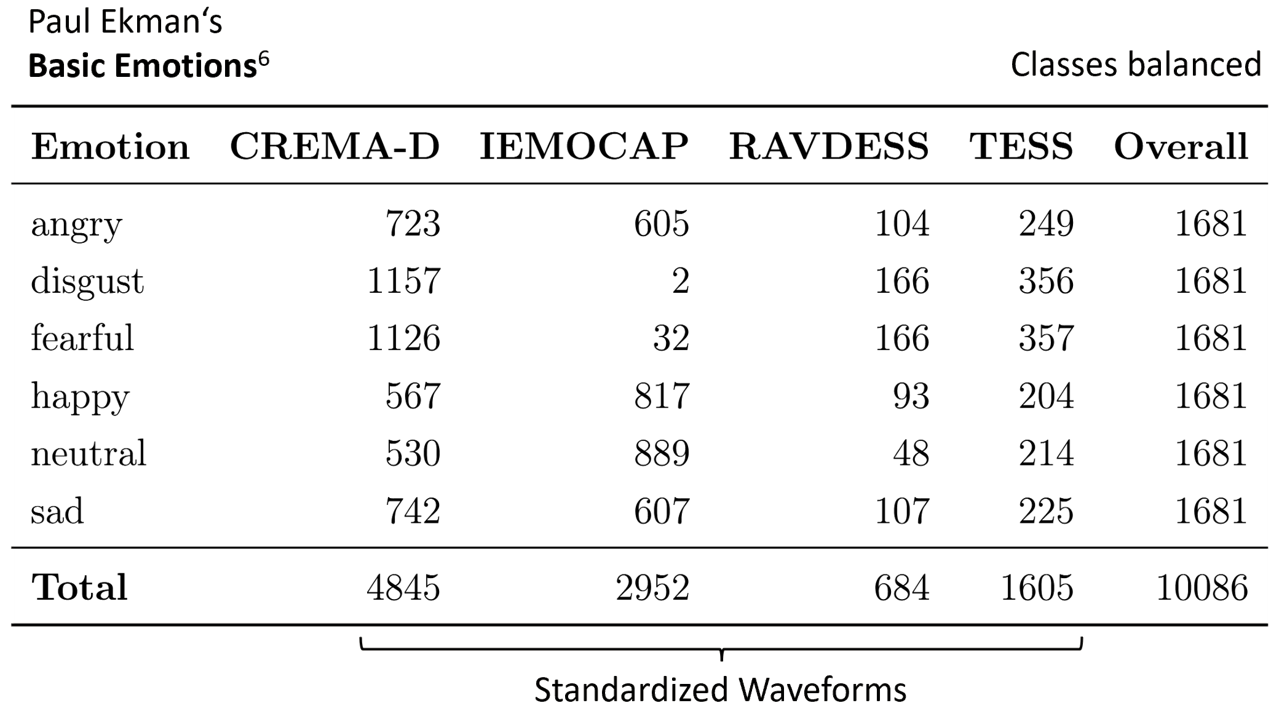
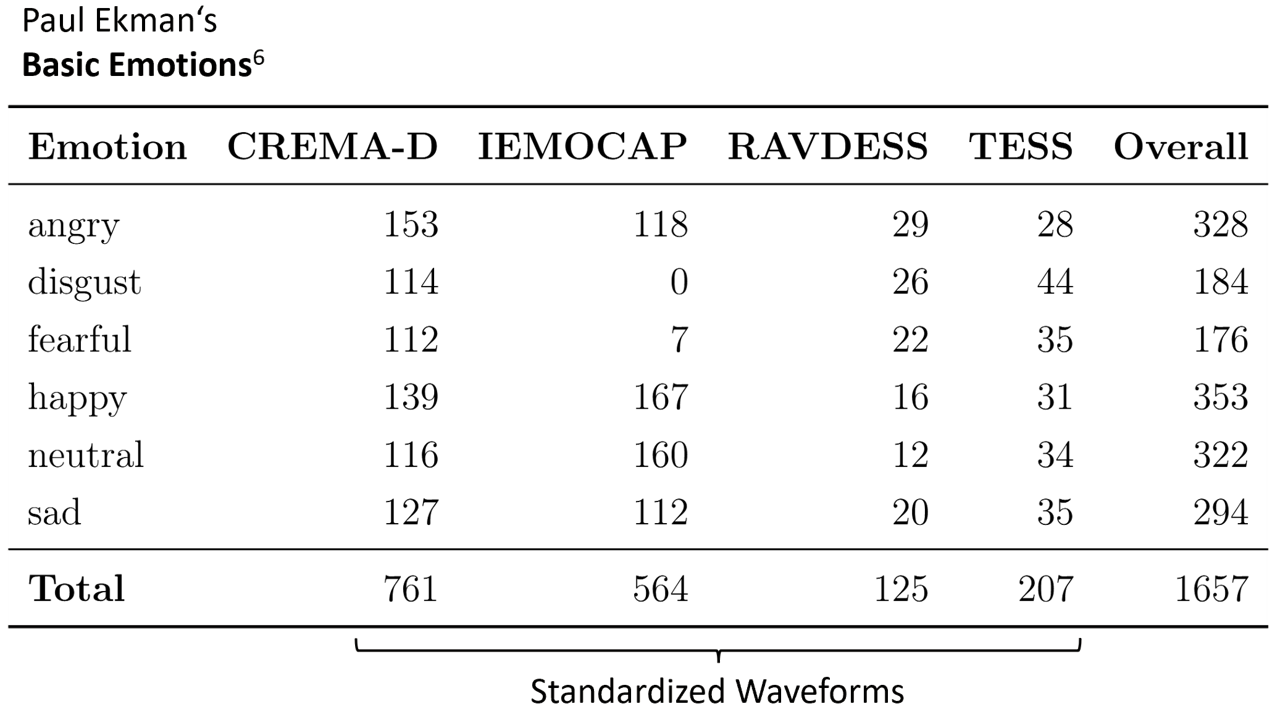
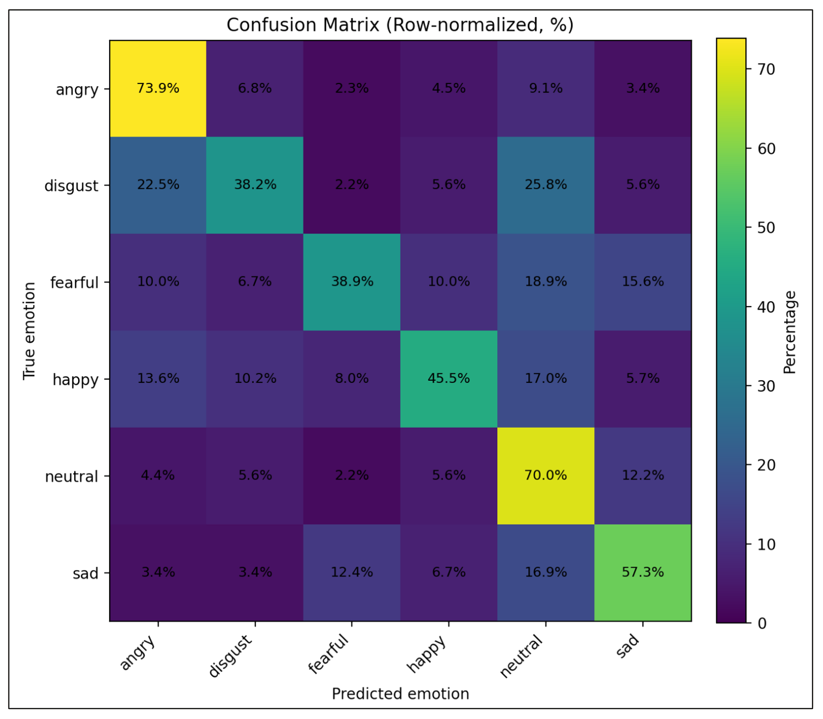
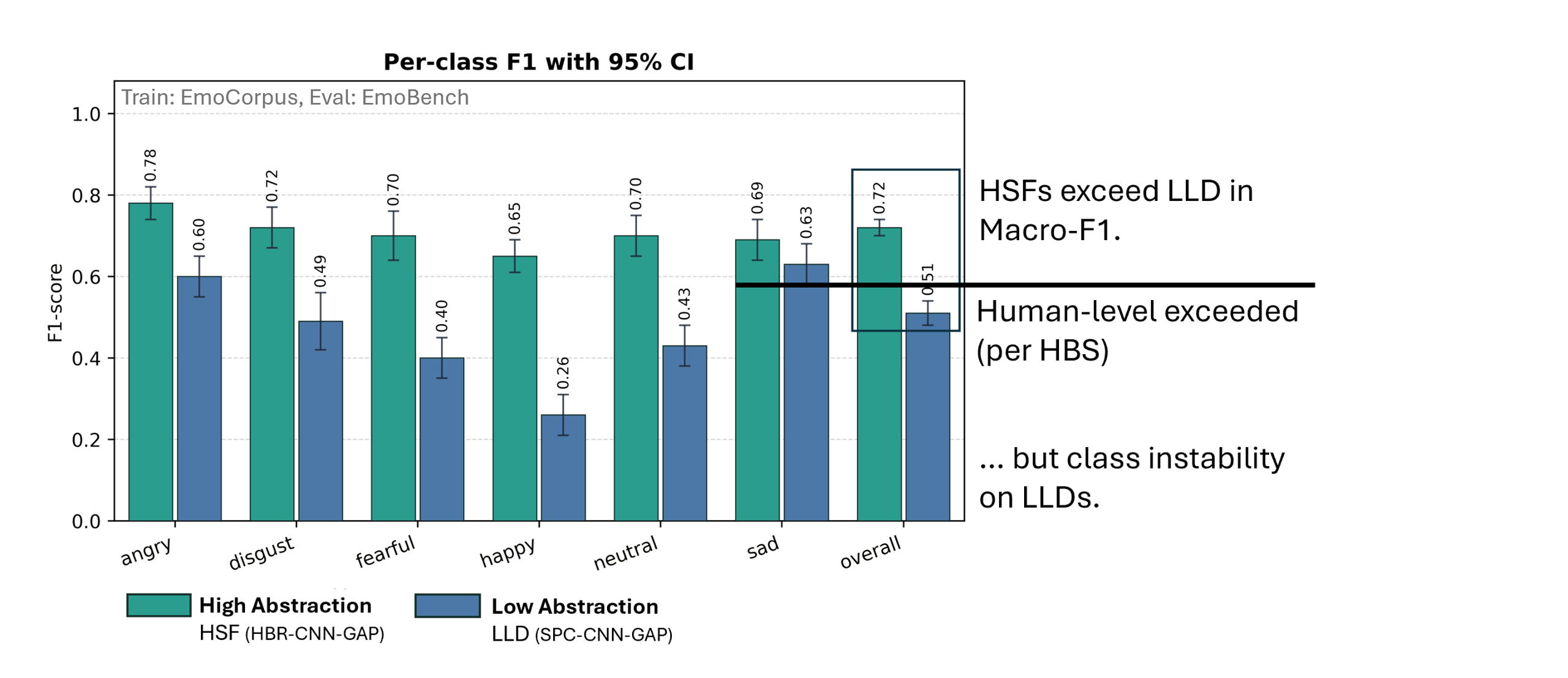
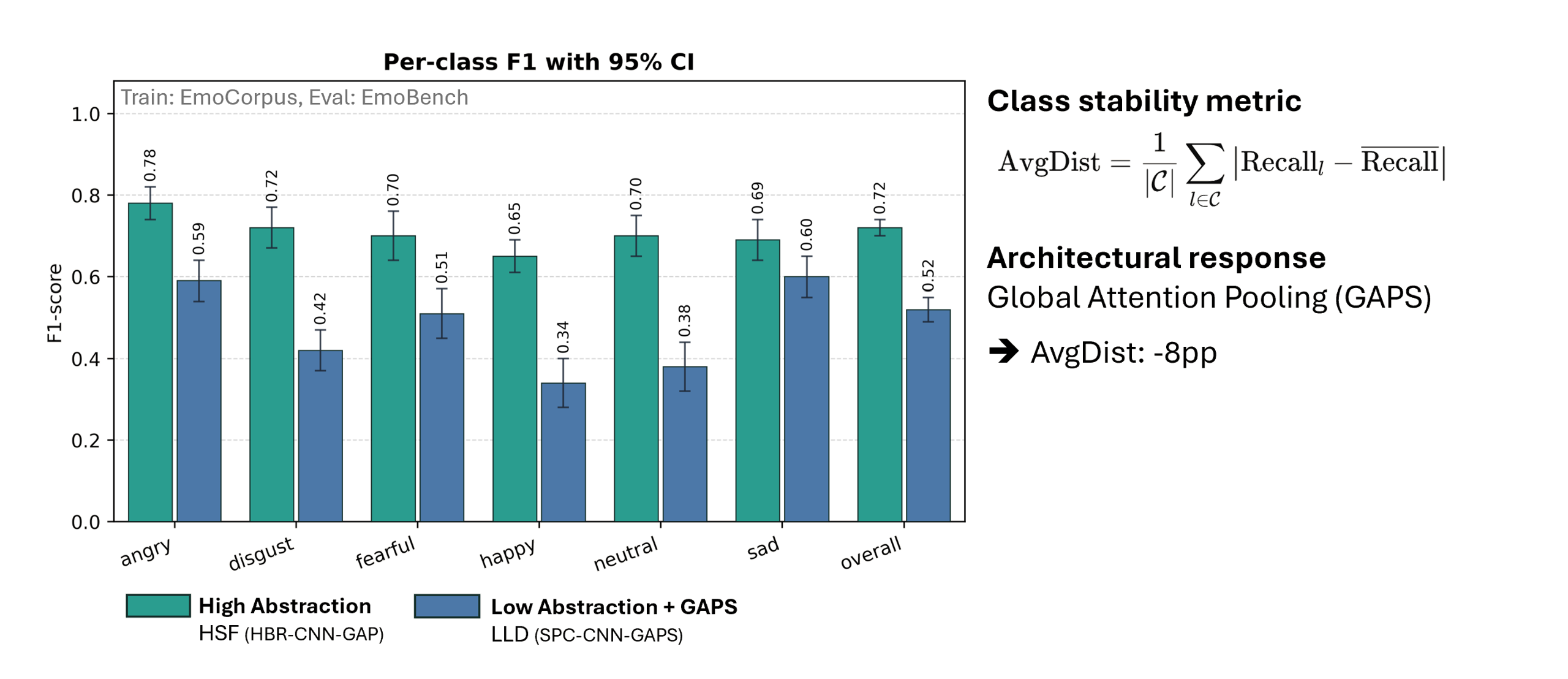
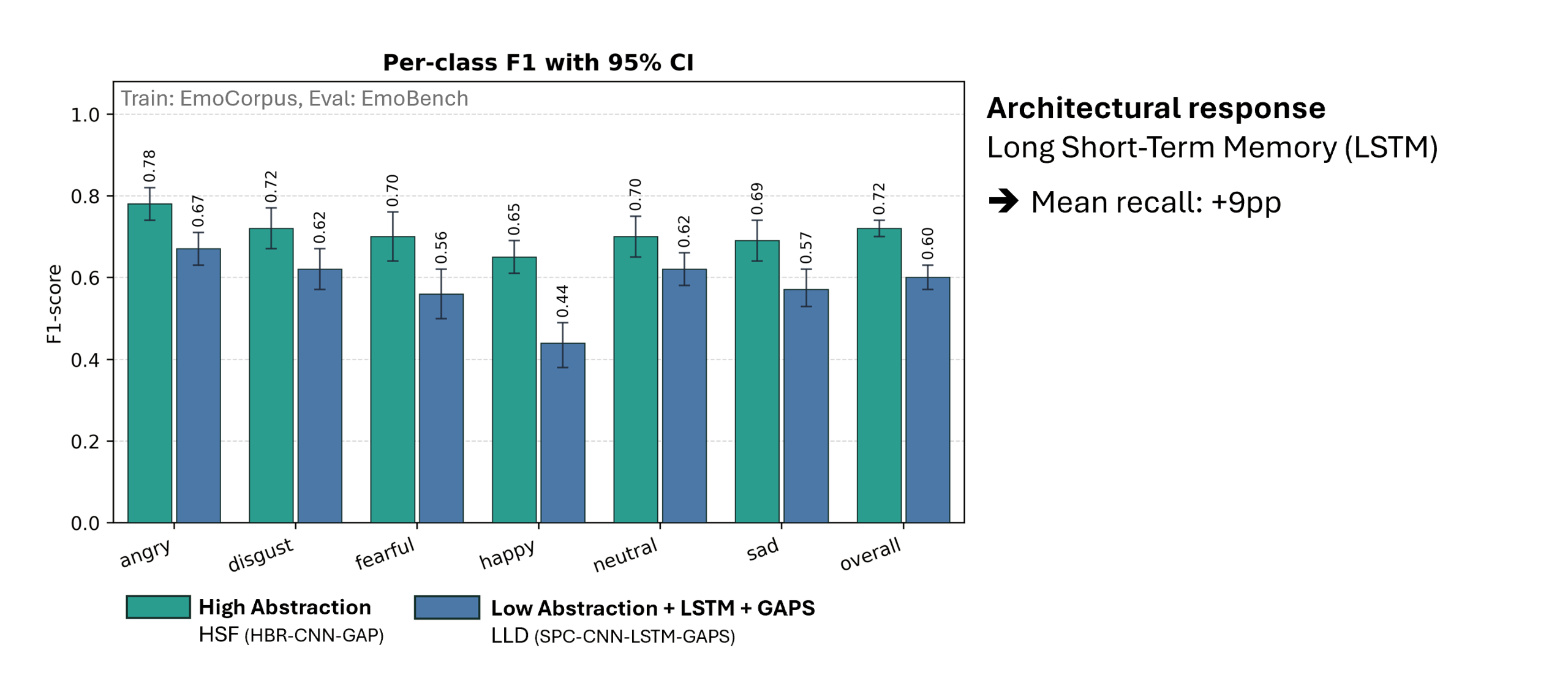
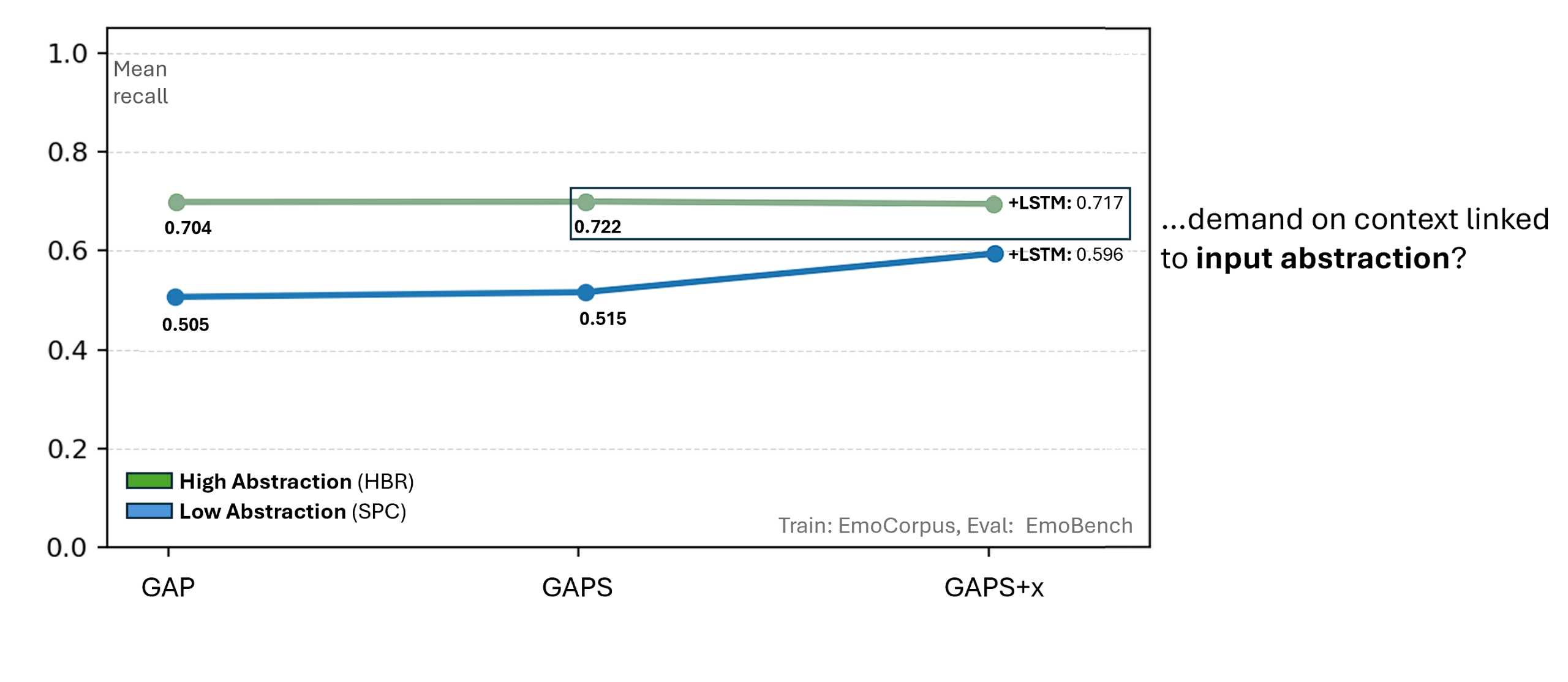
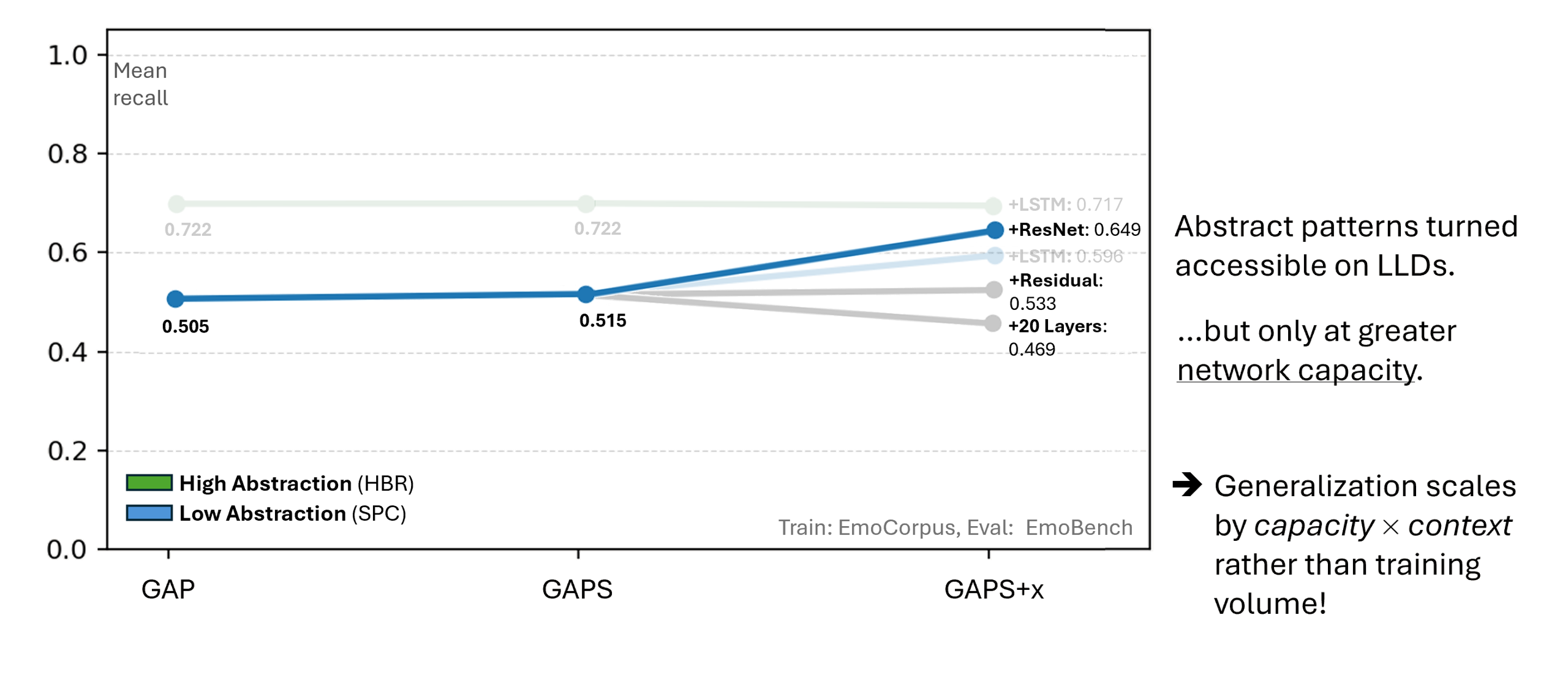
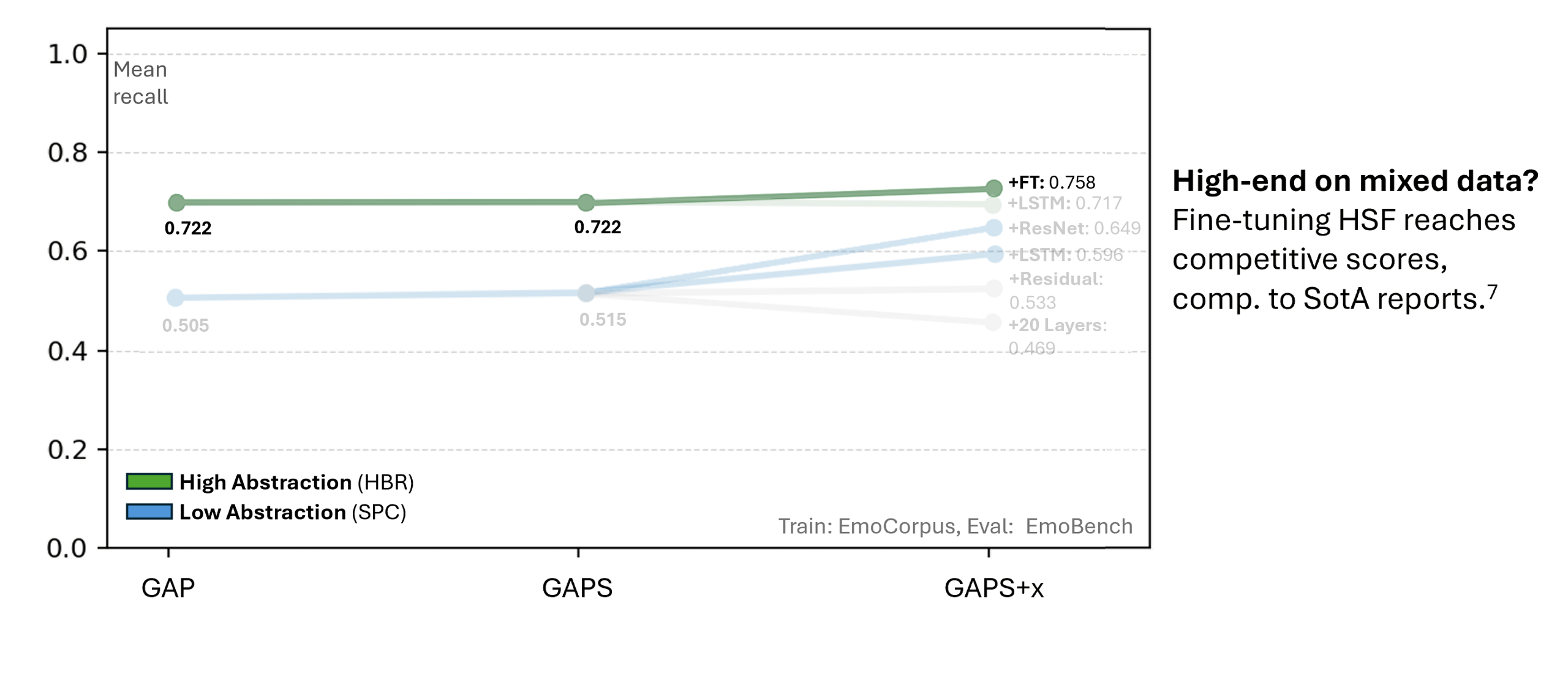
At the core of this project lies the classification of short speech recordings by emotions. To this end, key technical concepts are related, more than 30 pipelines were implemented, and a well-founded paradigm for competitive architectures derived. In this context, EmoCorpus is introduced, an altered aggregation of widely used emotion-labeled audio datasets. Its counterpart, EmoBench, is distinctly partitioned to enable reproducible evaluations. Pipelines based on Low-Level Descriptors (LLDs) achieved strong performances on low variance data after being augmented with either global attention mechanisms or Long Short-Term Memory (LSTM), reaching accuracies of up to 99.5%. Notably, LSTM exhibited the opposite effect for abstract representations (HSFs). These representations, however, attained the highest accuracy on high-variance data (up to 73.5%) once encoder fine-tuning was enabled. The Human Baseline Study (HBS) complemented the SER results by assessing the performance of participants from seven countries on data drawn from EmoCorpus and EmoBench.